We propose a method for discovering and visualizing the differences between two learned
representations, enabling more direct and interpretable
model comparisons. We validate our method, which we call Representational Differences
Explanations (RDX), by using it to compare models with
known conceptual differences and demonstrate that it recovers meaningful
distinctions where existing explainable AI (XAI) techniques fail. Applied to
state-of-the-art models on challenging subsets of the ImageNet and iNaturalist datasets, RDX
reveals both insightful representational differences and
subtle patterns in the data.
Although comparison is a cornerstone of scientific
analysis, current tools in machine learning, namely post hoc XAI methods,
struggle to support model comparison effectively. Our work addresses this
gap by introducing an effective and explainable tool for contrasting model
representations.
We train a model on a subset of MNIST with the digits 3, 5, and 8. We compare representations from two checkpoints, one with strong performance (95%) and one with expert performance (98%). Below we show PCA plots for each model's representation of the dataset. It is clear that the expert model has better separation between clusters for each digit.

We apply existing dictionary learning methods: SAE, NMF, PCA, Top-K SAE, and KMeans to each model and generate explanations (image grids). We also test two recent explainability methods, Universal SAE and Non-Linear Multi-dimensional Concept Discovery (NLMCD) that are explicitly designed for model comparison. Below we show the image grids generated by each method for each model's representation. We find that the explanations generated by baseline XAI methods do not identify clear differences between the strong (MS) and expert (ME) models. For example, the KMeans explanations are nearly identical for both models.







Below we show the output of RDX. Our method generates an explanations that answers the question: what does model A considers to be more similar than model B (and vice versa)? This means, in the left panel, the images within each image grid are considered more similar by model A than by model B. We can see that model A has some cleanly grouped 3s (grid 1 and 2) and 5s (grid 3) that model B considers to be dissimilar. On the right, we see that model B considers digits from different classes more similar than model A does (grid 2 and 3). Now, if we try to guess the models corresponding to model A and model B, we can intuit that model B is MS since we saw that MS has more mixing between the classes. Check out our demo/game to compare RDX explanations to the baselines on several other comparison tasks!
RDX aims to identify images that are close together in one model's representation, but far apart in the other model's representation. For example, in the figure, we can see that the green points are tightly grouped in the MS representation, but spread apart in the ME representation. We achieve this by constructing a graph for each representation and clustering the difference between graphs. In the last column, we show image grids corresponding to each cluster (indicated by color). Each cluster corresponds to some concept. The green concept shows that MS confuses some 3s, 5s, and 8s that ME categorizes correctly. We can see this more clearly in the second slide. This result partially explains the performance difference between the models.
Dictionary-learning (DL) methods like NMF learn a linear combination of concept vectors to approximate the original representation. To visualize concept vectors, we select the top-k images with the largest coefficients for a particular concept. In the figure above (panel 1 and 2), we visualize the concept coefficients after applying NMF to MS and ME. We can see that concept 1 for MS and concept 2 for ME both activate most strongly for images of 5s. However, we can also see that concept 2 from ME shows more selectivity for 5s than concept 1 from MS. This information is unavailable to the user when visualizing the image grid for these two concepts (bottom), but is crucial for understanding the difference between the two models.
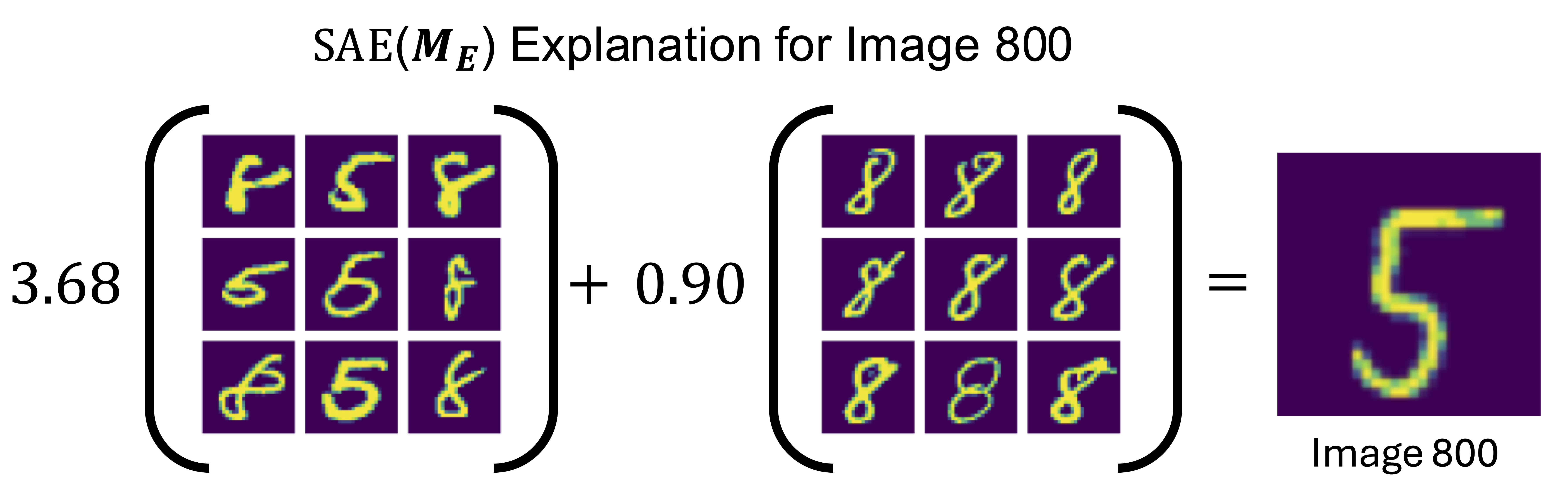
Additionally, DL methods generate linear combinations of concept vectors. Sometimes we need to consider the contributions of multiple concepts when thinking about an image. However, it is extremely difficult to gain meaning from looking at a weighted sum over image grids. How are we supposed to anticipate that the sum of these two concepts will lead to a fairly normal looking 5? This problem is amplified when we consider that the explanations might not accurately reflect the meaning of the concept vector, as we saw in the previous section.
Finally, we conduct comparisons in more realistic scenarios. In the top panel, we look for concepts that DINOv2 encodes that DINO does not know. We find that DINOv2 has a better organization of various types of primates from ImageNet that likely contributes to its improved performance on fine-grained categories. In the bottom panel, we look for concepts that a CLIP model fine-tuned on INaturalist discovers that the original CLIP model did not know. We find that the fine-tuned model has distinct groups for fall-colored Red Maple leaves and fall-colored and green Silver Maple leaves. When we look at the original CLIP model, we see that it has much more mixing for these same images. In both settings, we are able to isolate concepts unique to one of the two models, allowing us to make hypotheses about the differences between them. We include several more examples in our pre-print.
@article{kondapaneni2025repdiffexp,
title={Representational Difference Explanations},
author={Kondapaneni, Neehar and Mac Aodha, Oisin and Perona, Pietro},
journal={arXiv preprint arXiv:2505.23917},
year={2025}
}